Nazli Ikizler and David Forsyth, “Searching video for complex activities with finite state models” IEEE Conference on Computer Vision and Pattern Recognition, 2007
A journal version is in review currently.
Finding: We have compared with discriminative methods applied to tracker data; our method offers significantly improved performance. We
have obtained experimental evidence that our method is robust to view direction and is unaffected by the changes of clothing
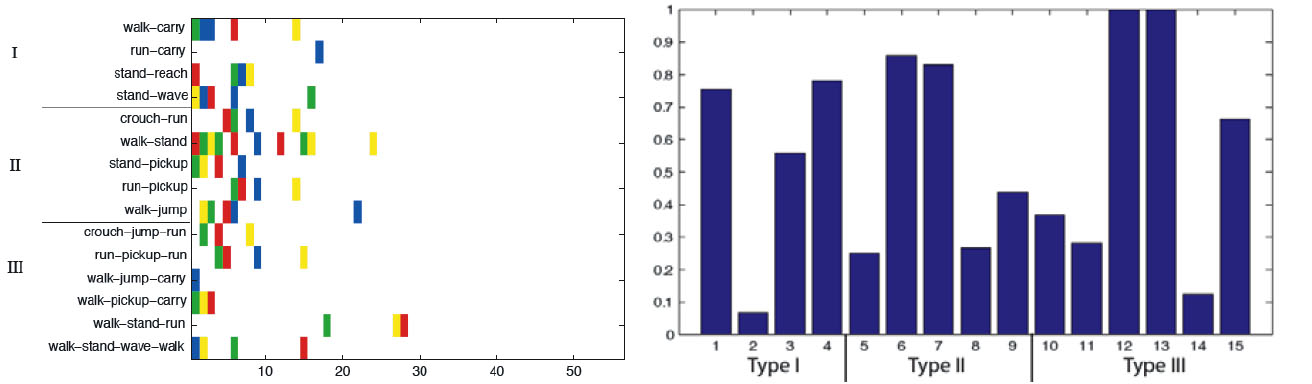
Activity modelling using finite state automata: Our representation can give quite accurate results for complex motion queries, regardless of the clothing worn by the subject. Left: The results of ranking for 15 queries over our video collection (using k=40 in k-means). In this image, a colored pixel indicates a relevant video. An ideal search would result in an image where all the colored pixels are on the left of the image. Each color represents a different outfit. Note that the choice of the outfit doesn't affect the performance. We have three types of query here. Type I: single activities where there is a different action for legs and arms (ex: walk-carry). Type II: two consecutive actions like crouch followed by a
run. Type III: activities that are more complex, consisting of three consecutive actions where different body parts may be doing different things (ex: walk-stand-walk for legs; walk-wave-walk for arms. Right: Average precision values for each query. Overall, mean average precision for HMM models using 40 clusters is 0.5636.